Metodología de Ralph Kimball – Ciclo de Vida
La metodología se basa
en lo que Kimball denomina Ciclo de Vida Dimensional del Negocio
(Business Dimensional Lifecycle). Este ciclo de vida del proyecto de
Data Warehouse, está basado en cuatro principios básicos:
- Centrarse en el negocio: Hay que concentrarse en la identificación de los requerimientos del negocio y su valor asociado, y usar estos esfuerzos para desarrollar relaciones sólidas con el negocio, agudizando el análisis del mismo y la competencia consultiva de los implementadores.
- Construir una infraestructura de información adecuada: Diseñar una base de información única, integrada, fácil de usar, de alto rendimiento donde se reflejará la amplia gama de requerimientos de negocio identificados en la organización.
- Realizar entregas en incrementos significativos: Crear el almacén de datos (DW) en incrementos entregables en plazos de 6 a 12 meses. Hay que usar el valor de negocio de cada elemento identificado para determinar el orden de aplicación de los incrementos. En esto la metodología se parece a las metodologías ágiles de construcción de software.
- Ofrecer la solución completa: Proporcionar todos los elementos necesarios para entregar valor a los usuarios de negocios. Para comenzar, esto significa tener un almacén de datos sólido bien diseñado, con calidad probada, y accesible. También se deberá entregar herramientas de consulta Ad Hoc, aplicaciones para informes y análisis avanzado, capacitación, soporte, sitio web y documentación.
 |
| Ciclo de vida de BI/DW, fuente: Kimball & Ross |
Planificación del proyecto
La planificación busca identificar la definición y el alcance del proyecto, incluyendo las justificaciones del negocio y las evaluaciones de factibilidad.
Definición de los requisitos del negocio.
En este proceso se busca interpretación correcta de los diferentes niveles de requerimientos expresados por los distintos grupos de usuarios.
Diseño de la arquitectura
Los entornos de almacén de datos requieren la integración de numerosas tecnologías. Se deben tener en cuenta tres factores: los requerimientos del negocio, los actuales entornos técnicos y las directrices técnicas y estratégicas futuras planificadas por la compañía para poder establecer el diseño de la arquitectura técnica del entorno de almacén de datos.
Para ello propone un proceso para asegurar un correcto diseño arquitectónico sin extenderse demasiado en el tiempo.
Utilizando el diseño de arquitectura como marco es necesario evaluar y seleccionar los componentes específicos de la arquitectura, como la plataforma de hardware, el motor de base de datos, las herramientas de ETC, las herramientas de acceso, etc.
Diseño del Modelo dimensional
Una vez entendido los objetivos del sistema DW/BI, empecemos a considerar los principios del modelado dimensional. El modelado dimensional es ampliamente aceptado como la técnica preferida para la presentación de los datos analíticos, ya que aborda simultáneamente estos 2 requerimientos:
• Entregar datos que sean entendibles para el usuario.
• Generar consultas rápidas.
El modelado dimensional es una técnica desarrollada hace muchos años para el diseño de bases de datos simples. La sencillez es importante ya que garantiza que los usuarios puedan fácilmente entender los datos, así como también permite que el software navegue y entregue los resultados eficientemente.
En el proceso de diseño dimensional propuesto por Kimball se distinguen varias etapas:
El diseño físico de la base de datos se focaliza sobre la selección de las estructuras necesarias para soportar el diseño lógico. Generalmente esta es la etapa donde se definen las estructuras del almacén de datos o área de datos.
Diseño y construcción de procesos ETL
Esta etapa es una de las más importantesen un proyecto de inteligencia de negocio. Las principales actividades de esta fase del ciclo de vida son: la extracción, la transformación y la carga. Se definen como procesos de extracción aquellos requeridos para obtener los datos que permitirán efectuar la carga del Modelo Físico diseñado. Así mismo, se definen como procesos de transformación los procesos para convertir o recodificar los datos fuente a fin de poder efectuar la carga efectiva del Modelo Físico. Por otra parte, los procesos de carga de datos son los procesos requeridos para poblar el almacén de datos.
En este proceso se busca interpretación correcta de los diferentes niveles de requerimientos expresados por los distintos grupos de usuarios.
Diseño de la arquitectura
Los entornos de almacén de datos requieren la integración de numerosas tecnologías. Se deben tener en cuenta tres factores: los requerimientos del negocio, los actuales entornos técnicos y las directrices técnicas y estratégicas futuras planificadas por la compañía para poder establecer el diseño de la arquitectura técnica del entorno de almacén de datos.
Para ello propone un proceso para asegurar un correcto diseño arquitectónico sin extenderse demasiado en el tiempo.
- Establecer un Grupo de Trabajo de Arquitectura
- Requisitos relacionados con la arquitectura
- Documento de requisitos arquitectónicos
- Desarrollo de un modelo arquitectónico de alto nivel
- Diseño y especificación de los subsistemas
- Determinar las fases de aplicación de la Arquitectura
- Documento de la Arquitectura Técnica
- Revisar y finalizar la Arquitectura Técnica
Utilizando el diseño de arquitectura como marco es necesario evaluar y seleccionar los componentes específicos de la arquitectura, como la plataforma de hardware, el motor de base de datos, las herramientas de ETC, las herramientas de acceso, etc.
Diseño del Modelo dimensional
Una vez entendido los objetivos del sistema DW/BI, empecemos a considerar los principios del modelado dimensional. El modelado dimensional es ampliamente aceptado como la técnica preferida para la presentación de los datos analíticos, ya que aborda simultáneamente estos 2 requerimientos:
• Entregar datos que sean entendibles para el usuario.
• Generar consultas rápidas.
El modelado dimensional es una técnica desarrollada hace muchos años para el diseño de bases de datos simples. La sencillez es importante ya que garantiza que los usuarios puedan fácilmente entender los datos, así como también permite que el software navegue y entregue los resultados eficientemente.
En el proceso de diseño dimensional propuesto por Kimball se distinguen varias etapas:
- Definición del proceso de negocio.
- Definición del grano
- Elección de las dimensiones
- Identificación de los hechos
El diseño físico de la base de datos se focaliza sobre la selección de las estructuras necesarias para soportar el diseño lógico. Generalmente esta es la etapa donde se definen las estructuras del almacén de datos o área de datos.
Diseño y construcción de procesos ETL
Esta etapa es una de las más importantesen un proyecto de inteligencia de negocio. Las principales actividades de esta fase del ciclo de vida son: la extracción, la transformación y la carga. Se definen como procesos de extracción aquellos requeridos para obtener los datos que permitirán efectuar la carga del Modelo Físico diseñado. Así mismo, se definen como procesos de transformación los procesos para convertir o recodificar los datos fuente a fin de poder efectuar la carga efectiva del Modelo Físico. Por otra parte, los procesos de carga de datos son los procesos requeridos para poblar el almacén de datos.
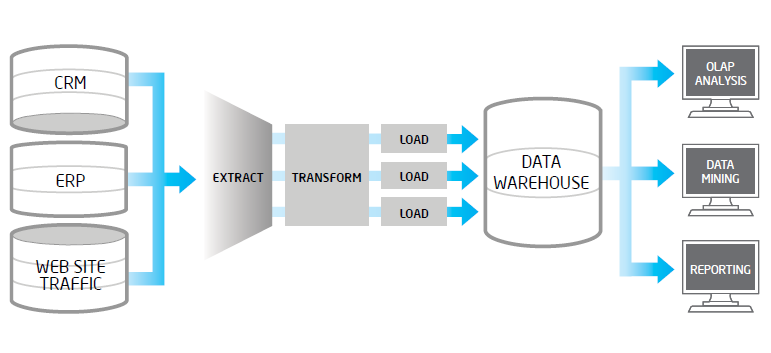 |
| Proceso ETL, fuente: dataprix |
Extract (Extracción): Es el proceso que recupera los datos físicamente de las distintas fuentes de información.
Transform (Transformación): Este proceso recupera los datos, de alta calidad, los estructura y sumariza en los distintos modelos de análisis. El resultado de este proceso es la obtención de datos limpios, consistentes, sumarizados y útiles.
Load (Carga): Este proceso valida que los datos que cargamos en el almacén de datos son consistentes con las definiciones y formatos del almacén de datos; los integra en los distintos modelos de las distintas áreas de negocio.
Especificación de aplicaciones para usuarios
No todos los usuarios del almacén de datos necesitan el mismo nivel de análisis. Es por ello que en esta etapa se identifican los roles o perfiles de usuarios para los diferentes tipos de aplicaciones necesarias en base al alcance de los perfiles detectados (gerencial, analista del negocio, vendedor, etc.)
ENTRADAS Y SALIDAS
Los pasos de entradas y salidas permiten la extracción de los datos de diferentes fuentes, además de la carga de información en archivos o bases de datos. Los pasos cubiertos en esta sección están en las carpeta Input y Output, en la sección de Design.
Entrada de archivo (Text file input): Este paso permite obtener la información de un archivo de texto, incluso en formato CSV. Para utilizar este paso, es necesario completar los siguientes campos:
• En la pestaña archivo (File), se debe agregar la dirección del archivo de texto en el campo “Archivo o directorio” (File or directory). Para agregar una dirección, presione el botón carpeta (Browse...) y seleccione el archivo. Una vez seleccionado el archivo, se agrega a la lista de archivos seleccionados presionando el botón “Agregar” (Add).
Es posible agregar varios archivos de texto con el mismo formato en el mismo paso.
• En la pestaña “Contenido” (Content),, se selecciona el “Tipo de archivo” (File type), el “Separador de los campos” (Separator), el “Agrupador de los datos” (Enclosure) y el “Formato del archivo” (Format).
• En la pestaña campos (Fields), se agregan los campos que contiene el archivo con el botón “Obtener campos” (Get fields).
No todos los usuarios del almacén de datos necesitan el mismo nivel de análisis. Es por ello que en esta etapa se identifican los roles o perfiles de usuarios para los diferentes tipos de aplicaciones necesarias en base al alcance de los perfiles detectados (gerencial, analista del negocio, vendedor, etc.)
Desarrollo de aplicaciones para usuarios
el desarrollo de las aplicaciones de los usuarios finales involucra configuraciones de los metadatos y construcción de reportes específicos.
Los usuarios acceden al almacén de datos por medio de herramientas de productividad basadas en GUI (Interfaz grafica de usuario). De hecho existen multitud de estas herramientas con las que proveer a los usuarios. Las herramientas pueden incluir software de consultas, generadores de reportes, procesamiento analítico en línea o herramientas de Minería de Datos dependiendo de los tipos de usuarios y sus requerimientos particulares. Sin embargo, una sola herramienta puede no satisfacer todos los requerimientos, por lo que quizás sea necesario la integración de herramientas hechas bajo petición expresa de los usuarios para satisfacer sus necesidades de consulta sobre el almacén de datos.
Los usuarios acceden al almacén de datos por medio de herramientas de productividad basadas en GUI (Interfaz grafica de usuario). De hecho existen multitud de estas herramientas con las que proveer a los usuarios. Las herramientas pueden incluir software de consultas, generadores de reportes, procesamiento analítico en línea o herramientas de Minería de Datos dependiendo de los tipos de usuarios y sus requerimientos particulares. Sin embargo, una sola herramienta puede no satisfacer todos los requerimientos, por lo que quizás sea necesario la integración de herramientas hechas bajo petición expresa de los usuarios para satisfacer sus necesidades de consulta sobre el almacén de datos.
Gestión del proyecto
La gestión del proyecto asegura que las actividades del ciclo de vida se lleven a cabo de manera sincronizada. La gestión del proyecto acompaña todo el ciclo de vida. Entre sus actividades principales se encuentra la monitorización del estado del proyecto y el acoplamiento entre los requerimientos del negocio y las restricciones de los sistemas de información para poder manejar correctamente las expectativas en ambos sentidos.
Datamart
Es una base de datos departamental, almacena información de un área específica. Dispone de una estructura óptima de los datos desde cualquier perspectiva. Se alimenta de los datos de una datawarehouse o integrar por sí mismo distintas fuentes de información.
Datawarehouse
Se caracteriza por integrar y depurar información de una o más fuentes distintas, posteriormente la procesa analizando sus perspectivas con mayor velocidad de repuesta. Este es el primero paso de cualquier BI. La estructura como se almacena la información es una ventaja en estas bases de datos.
Bill Inmon fue quien acuño este término y a pesar de su significado, asegura es mucho más que eso, en seguida algunas características:
La minera de datos es una tecnología emergente, permite explotar grandes bases de datos para explicar el comportamiento de los mismos en un contexto determinado.
Hace uso de prácticas estadísticas, algoritmos de búsqueda como los utilizados en la inteligencia artificial. Consta de 4 etapas que son las siguientes:
La gestión del proyecto asegura que las actividades del ciclo de vida se lleven a cabo de manera sincronizada. La gestión del proyecto acompaña todo el ciclo de vida. Entre sus actividades principales se encuentra la monitorización del estado del proyecto y el acoplamiento entre los requerimientos del negocio y las restricciones de los sistemas de información para poder manejar correctamente las expectativas en ambos sentidos.
Datamart
Es una base de datos departamental, almacena información de un área específica. Dispone de una estructura óptima de los datos desde cualquier perspectiva. Se alimenta de los datos de una datawarehouse o integrar por sí mismo distintas fuentes de información.
Datawarehouse
Se caracteriza por integrar y depurar información de una o más fuentes distintas, posteriormente la procesa analizando sus perspectivas con mayor velocidad de repuesta. Este es el primero paso de cualquier BI. La estructura como se almacena la información es una ventaja en estas bases de datos.
Bill Inmon fue quien acuño este término y a pesar de su significado, asegura es mucho más que eso, en seguida algunas características:
- Integrado.- Los datos deben integrarse en una estructura consistente.
- Temático.- Únicamente los datos que generan conocimiento se integran desde el entorno operacional, se ordenan por temas.
- Histórico.- Dado que guarda información que varía a través del tiempo es posible realizar comparaciones.
- No volátil.- Es de solo lectura y no se puede modificar.
La minera de datos es una tecnología emergente, permite explotar grandes bases de datos para explicar el comportamiento de los mismos en un contexto determinado.
Hace uso de prácticas estadísticas, algoritmos de búsqueda como los utilizados en la inteligencia artificial. Consta de 4 etapas que son las siguientes:
- Determinación de los objetivos.
- Pre procesamiento de los datos.
- Determinación del modelo.
- Análisis de los resultados.
Exploración de Procesos ETL mediante Pentaho Data Integration
ENTRADAS Y SALIDAS
Los pasos de entradas y salidas permiten la extracción de los datos de diferentes fuentes, además de la carga de información en archivos o bases de datos. Los pasos cubiertos en esta sección están en las carpeta Input y Output, en la sección de Design.
Entrada de archivo (Text file input): Este paso permite obtener la información de un archivo de texto, incluso en formato CSV. Para utilizar este paso, es necesario completar los siguientes campos:
• En la pestaña archivo (File), se debe agregar la dirección del archivo de texto en el campo “Archivo o directorio” (File or directory). Para agregar una dirección, presione el botón carpeta (Browse...) y seleccione el archivo. Una vez seleccionado el archivo, se agrega a la lista de archivos seleccionados presionando el botón “Agregar” (Add).
Es posible agregar varios archivos de texto con el mismo formato en el mismo paso.
• En la pestaña “Contenido” (Content),, se selecciona el “Tipo de archivo” (File type), el “Separador de los campos” (Separator), el “Agrupador de los datos” (Enclosure) y el “Formato del archivo” (Format).
• En la pestaña campos (Fields), se agregan los campos que contiene el archivo con el botón “Obtener campos” (Get fields).
 |
Para ver un ejemplo de este paso, abra la transformación Textfile input - fixed length.ktr dentro del directorio data-integration →samples→transformations
1. Seleccione el paso Dummy (do nothing).
2. Presione click derecho sobre el paso y luego seleccione la opción visualizar (Preview).
3. Aparecerá una ventana. Presione el botón ejecución rápida (Quick launch).
La visualización debe mostrar la siguiente información:

Entrada de tabla (Table input): Este paso permite obtener la información de una base de datos. Para utilizar este paso, es necesario completar los siguientes campos:
• Conexión (Connection): Muestra una lista desplegable de las conexiones definidas y compartidas.
• SQL: En esta área se coloca la consulta. La consulta debe estar adaptada a la base de datos a la que se vaya a conectar.

Para ver un ejemplo de este paso, abra la transformación Table Output - Tablename in field.ktr dentro del directorio data-integration →samples→transformations
1. Presione doble click sobre el paso Table input.
2. Presione el botón Vizualizar (Preview).
3. Aparecerá una ventana. Presione el botón (OK).
La visualización debe mostrar la siguiente información:

Entrada de excel (Microsoft Excel input): Este paso permite obtener la información de una o varias hojas de cálculos, siempre y cuando tengan el mismo formato. Para utilizar este paso, es necesario completar los siguientes campos:
• Al igual que el paso “Entrada de archivo”, en la pestaña archivos (Files), se debe agregar la dirección del archivo de la hoja de cálculo en el campo “Archivo o directorio” (File or directory). Para agregar una dirección, presione el botón “Carpeta” (Browse...) y seleccione la hoja de cálculo. Una vez seleccionada, se agrega a la lista de archivos seleccionados presionando el botón “Agregar” (Add). Es posible agregar varias hojas de cálculo en el mismo paso.
• En la pestaña hojas (Sheets), se selecciona la hoja donde se encuentra la información. Puede escribirse manualmente, o se puede seleccionar por medio de una lista, presionando el botón “Obtener nombres de hojas” (Get sheetname(s)...). Una vez seleccionada las hojas, se debe definir el inicio de los datos por medio de las filas y las columnas. Para ello, se debe considerar la hoja de cálculo como una matriz y especificar la fila y la columna (Start row y Start column) tomando el índice de las mismas. Por ejemplo, si los datos comienzan en las coordenadas B7, el valor de la fila sería 6 y el valor de la columna sería 1.
• En la pestaña campos (Fields), se agregan los campos que contiene el archivo con el botón “Obtener campos” (Get fields).

Para ver un ejemplo de este paso, abra la transformación Excel Input - XLS - XLSX - ODS reading.ktr dentro del directorio data-integration →samples→transformations, la cual tiene varios formatos de entrada de archivos Excel.
1. Presionar doble click (XLSX Input).
2. Presione el botón (Preview rows).
3. Aparecerá una ventana. Presione el botón (OK).
La visualización debe mostrar la siguiente información:

Generar registros (Generate rows): Este paso genera registros vacíos o iguales. Para utilizar este paso, es necesario completar los siguientes campos:
• El campo “Límite” (Limit) indica la cantidad de registros que generará.
• En la sección “Campos” (Fields) se pueden agregar de manera opcional, campos que se repetirán la cantidad de veces indicada en el límite. En esta sección se debe agregar el “Nombre del campo” (Name), el “Tipo de campo” (Type) y el “Valor” (Value) como campos principales.

Para ver un ejemplo de este paso, abra la transformación Generate Row - basics.ktr dentro del directorio data-integration →samples→transformations
1. Seleccione el paso Dummy (do nothing).
2. Presione click derecho sobre el paso y luego seleccione la opción visualizar (Preview).
3. Aparecerá una ventana. Presione el botón ejecución rápida (Quick launch).
La visualización debe mostrar la siguiente información:

Obtener información del sistema (Get system info): Este paso permite obtener información del sistema, tales como fechas, información de la transformación, argumentos, entre otros. Para utilizar este paso, es necesario completar los siguientes campos:
• En la sección “Campos” (Fields), se debe colocar el “Nombre del campo” (Name) y el “Tipo de información” (Type) que tendrá.

Para ver un ejemplo de este paso, abra la transformación Get System Info - Command Line Argument and filter.ktr dentro del directorio data-integration →samples→transformations.
1. Seleccione el paso Dummy (do nothing).
2. Presione click derecho sobre el paso y luego seleccione la opción visualizar (Preview).
3. Aparecerá una ventana. Presione el botón ejecución rápida (Quick launch).
La visualización debe mostrar la siguiente información:

Salida a archivo (Text file output): Este paso permite escribir la información del flujo en un archivo de texto. Para utilizar este paso, es necesario completar los siguientes campos:
• En la pestaña “Archivo” (File) se debe agregar el archivo de destino en el campo “Nombre de archivo” (Filename).
• En la pestaña “Contenido” (Content), se establece el “Separador de los campos” (Separator), el “Agrupador de los datos” (Enclosure) y la “Extensión del archivo” (Extension).
• En la pestaña “Campos” (Fields) se agregan los campos que serán cargados en el archivo con el botón “Obtener campos” (Get fields).

Para ver un ejemplo de este paso, abra la transformación Text File Output - Number formatting.ktr dentro del directorio data-integration →samples→transformations.
1. Ejecute la transformación con el botón Run, ubicado en la parte superior del panel derecho.
2. Aparecerá una ventana. Presione el botón ejecución (Launch).
La ejecución de la transformación generará un archivo de texto en la carpeta data-integration →samples→transformations →output, llamado number_formatting_sample.txt. Abra el archivo y verifique su contenido.
Salida a tabla (Table output): Este paso permite escribir la información del flujo en una tabla de base de datos. Para utilizar este paso, es necesario completar los siguientes campos:
• Conexión (Connection): Muestra una lista desplegable de las conexiones definidas y compartidas.
• Esquema (Target schema): Esquema donde se encuentra la tabla destino.
• Tabla (Target table): Nombre de la tabla destino.
• Especificar los campos (Especify database fields): Al marcar esta opción, puedes especificar los campos del flujo que serán guardados en la tabla.
• En la pestaña “Campos de la tabla” (Database fields), se establece la relación de los campos que serán guardados en la tabla. El “Campo de la tabla” (Table field) es el nombre del campo en la tabla, y “Campo del flujo” (Stream field) es el nombre del campo que proviene del ETL.
• Si la tabla especificada no existe en la base de datos, es posible crearla con el botón SQL.

Para ver un ejemplo de este paso, abra la transformación Table Output - Tablename in field.ktr dentro del directorio data-integration →samples→transformations.
1. Seleccione el paso Table output.
2. Presione click derecho sobre el paso y luego seleccione la opción visualizar (Preview).
3. Aparecerá una ventana. Presione el botón ejecución rápida (Quick launch).
La visualización debe mostrar la siguiente información:

1. Seleccione el paso Dummy (do nothing).
2. Presione click derecho sobre el paso y luego seleccione la opción visualizar (Preview).
3. Aparecerá una ventana. Presione el botón ejecución rápida (Quick launch).
La visualización debe mostrar la siguiente información:
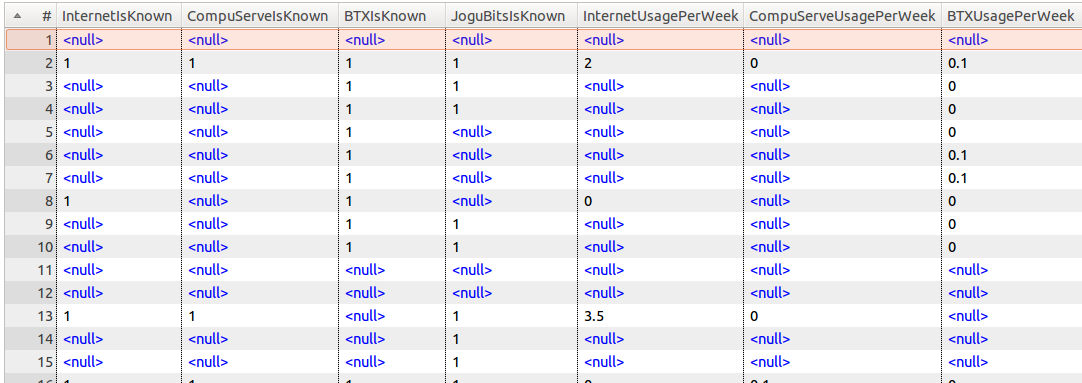
Entrada de tabla (Table input): Este paso permite obtener la información de una base de datos. Para utilizar este paso, es necesario completar los siguientes campos:
• Conexión (Connection): Muestra una lista desplegable de las conexiones definidas y compartidas.
• SQL: En esta área se coloca la consulta. La consulta debe estar adaptada a la base de datos a la que se vaya a conectar.

Para ver un ejemplo de este paso, abra la transformación Table Output - Tablename in field.ktr dentro del directorio data-integration →samples→transformations
1. Presione doble click sobre el paso Table input.
2. Presione el botón Vizualizar (Preview).
3. Aparecerá una ventana. Presione el botón (OK).
La visualización debe mostrar la siguiente información:

Entrada de excel (Microsoft Excel input): Este paso permite obtener la información de una o varias hojas de cálculos, siempre y cuando tengan el mismo formato. Para utilizar este paso, es necesario completar los siguientes campos:
• Al igual que el paso “Entrada de archivo”, en la pestaña archivos (Files), se debe agregar la dirección del archivo de la hoja de cálculo en el campo “Archivo o directorio” (File or directory). Para agregar una dirección, presione el botón “Carpeta” (Browse...) y seleccione la hoja de cálculo. Una vez seleccionada, se agrega a la lista de archivos seleccionados presionando el botón “Agregar” (Add). Es posible agregar varias hojas de cálculo en el mismo paso.
• En la pestaña hojas (Sheets), se selecciona la hoja donde se encuentra la información. Puede escribirse manualmente, o se puede seleccionar por medio de una lista, presionando el botón “Obtener nombres de hojas” (Get sheetname(s)...). Una vez seleccionada las hojas, se debe definir el inicio de los datos por medio de las filas y las columnas. Para ello, se debe considerar la hoja de cálculo como una matriz y especificar la fila y la columna (Start row y Start column) tomando el índice de las mismas. Por ejemplo, si los datos comienzan en las coordenadas B7, el valor de la fila sería 6 y el valor de la columna sería 1.
• En la pestaña campos (Fields), se agregan los campos que contiene el archivo con el botón “Obtener campos” (Get fields).

Para ver un ejemplo de este paso, abra la transformación Excel Input - XLS - XLSX - ODS reading.ktr dentro del directorio data-integration →samples→transformations, la cual tiene varios formatos de entrada de archivos Excel.
1. Presionar doble click (XLSX Input).
2. Presione el botón (Preview rows).
3. Aparecerá una ventana. Presione el botón (OK).
La visualización debe mostrar la siguiente información:

Generar registros (Generate rows): Este paso genera registros vacíos o iguales. Para utilizar este paso, es necesario completar los siguientes campos:
• El campo “Límite” (Limit) indica la cantidad de registros que generará.
• En la sección “Campos” (Fields) se pueden agregar de manera opcional, campos que se repetirán la cantidad de veces indicada en el límite. En esta sección se debe agregar el “Nombre del campo” (Name), el “Tipo de campo” (Type) y el “Valor” (Value) como campos principales.

Para ver un ejemplo de este paso, abra la transformación Generate Row - basics.ktr dentro del directorio data-integration →samples→transformations
1. Seleccione el paso Dummy (do nothing).
2. Presione click derecho sobre el paso y luego seleccione la opción visualizar (Preview).
3. Aparecerá una ventana. Presione el botón ejecución rápida (Quick launch).
La visualización debe mostrar la siguiente información:

Obtener información del sistema (Get system info): Este paso permite obtener información del sistema, tales como fechas, información de la transformación, argumentos, entre otros. Para utilizar este paso, es necesario completar los siguientes campos:
• En la sección “Campos” (Fields), se debe colocar el “Nombre del campo” (Name) y el “Tipo de información” (Type) que tendrá.

Para ver un ejemplo de este paso, abra la transformación Get System Info - Command Line Argument and filter.ktr dentro del directorio data-integration →samples→transformations.
1. Seleccione el paso Dummy (do nothing).
2. Presione click derecho sobre el paso y luego seleccione la opción visualizar (Preview).
3. Aparecerá una ventana. Presione el botón ejecución rápida (Quick launch).
La visualización debe mostrar la siguiente información:

Salida a archivo (Text file output): Este paso permite escribir la información del flujo en un archivo de texto. Para utilizar este paso, es necesario completar los siguientes campos:
• En la pestaña “Archivo” (File) se debe agregar el archivo de destino en el campo “Nombre de archivo” (Filename).
• En la pestaña “Contenido” (Content), se establece el “Separador de los campos” (Separator), el “Agrupador de los datos” (Enclosure) y la “Extensión del archivo” (Extension).
• En la pestaña “Campos” (Fields) se agregan los campos que serán cargados en el archivo con el botón “Obtener campos” (Get fields).

Para ver un ejemplo de este paso, abra la transformación Text File Output - Number formatting.ktr dentro del directorio data-integration →samples→transformations.
1. Ejecute la transformación con el botón Run, ubicado en la parte superior del panel derecho.
2. Aparecerá una ventana. Presione el botón ejecución (Launch).
La ejecución de la transformación generará un archivo de texto en la carpeta data-integration →samples→transformations →output, llamado number_formatting_sample.txt. Abra el archivo y verifique su contenido.
Salida a tabla (Table output): Este paso permite escribir la información del flujo en una tabla de base de datos. Para utilizar este paso, es necesario completar los siguientes campos:
• Conexión (Connection): Muestra una lista desplegable de las conexiones definidas y compartidas.
• Esquema (Target schema): Esquema donde se encuentra la tabla destino.
• Tabla (Target table): Nombre de la tabla destino.
• Especificar los campos (Especify database fields): Al marcar esta opción, puedes especificar los campos del flujo que serán guardados en la tabla.
• En la pestaña “Campos de la tabla” (Database fields), se establece la relación de los campos que serán guardados en la tabla. El “Campo de la tabla” (Table field) es el nombre del campo en la tabla, y “Campo del flujo” (Stream field) es el nombre del campo que proviene del ETL.
• Si la tabla especificada no existe en la base de datos, es posible crearla con el botón SQL.

Para ver un ejemplo de este paso, abra la transformación Table Output - Tablename in field.ktr dentro del directorio data-integration →samples→transformations.
1. Seleccione el paso Table output.
2. Presione click derecho sobre el paso y luego seleccione la opción visualizar (Preview).
3. Aparecerá una ventana. Presione el botón ejecución rápida (Quick launch).
La visualización debe mostrar la siguiente información:

Para vizualizar más ejemplos ir a la carpeta data-integration →samples→ transformations ejeucatar las transformaciones y verificar los resultados.
No hay comentarios.:
Publicar un comentario
"Hay una fuerza motriz más poderosa que el vapor, la electricidad y la energía atómica. Esa fuerza es la voluntad"- Albert Einstein
Tú comentario nos ayuda a Mejorar..... Gracias!!!